Method Overview
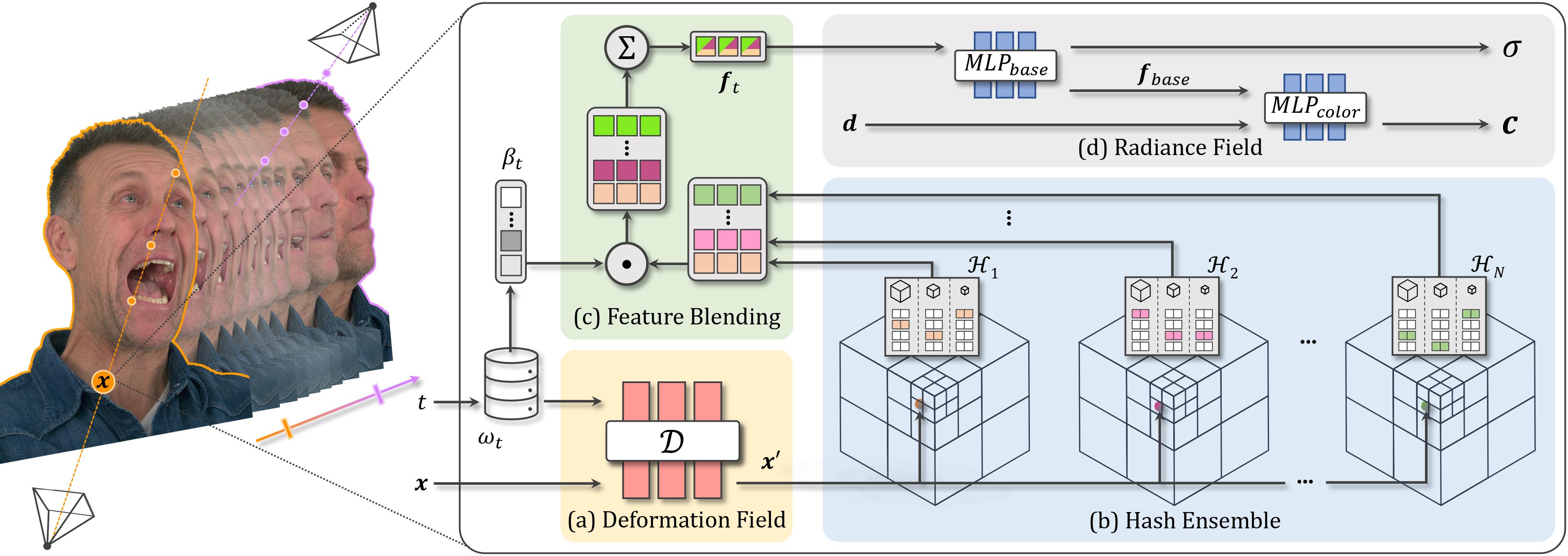
NeRSemble represents a spatio-temporal radiance field for dynamic NVS using volume rendering (left). On the right side, we show how NeRSemble obtains a density 𝜎(x) and color value c(x, d) for a point x on a ray at time 𝑡:
- Given the deformation code 𝝎𝑡 the point x is warped to x′ = D(x, 𝝎𝑡 ) in the canonical space.
- The resulting point is used to query features H𝑖(x′) from the 𝑖-th hash grid in our ensemble.
- The resulting features are blended using weights 𝛽𝑡 . Note that both 𝝎𝑡 and 𝛽𝑡 contribute to explaining temporal changes.
- We predict density 𝜎(x) and view-dependent color c(x, d) from the blended features using an efficient rendering head consisting of two small MLPs.