Avatar Animation via NPHM
A DiffusionAvatar can also be controlled via the underlying NPHM. We obtain expression codes zexp by interpolating between several target expressions. Using rasterization and our diffusion-based neural renderer, the expression codes are translated into a realistic avatar with viewpoint control.
Method Overview
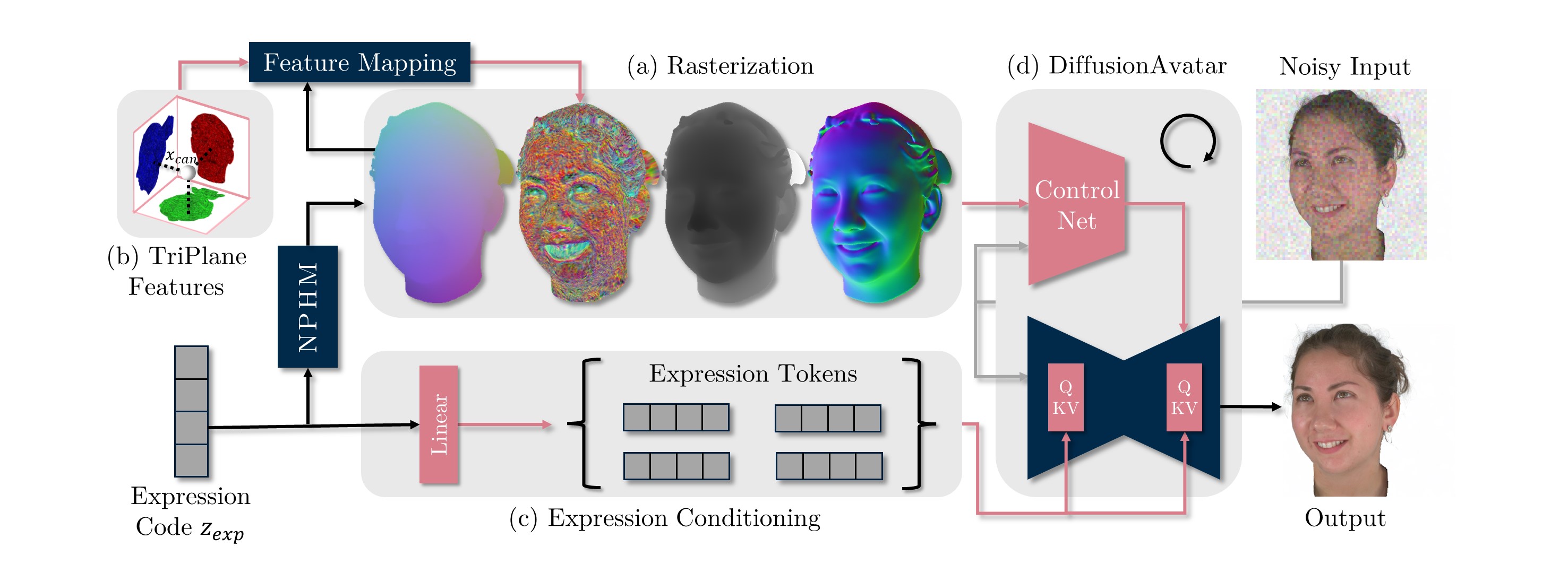
DiffusionAvatars decodes an NPHM expression code zexp in two ways to obtain a realistic image:
- We first extract an NPHM mesh and rasterize it from the desired viewpoint, giving us canonical coordinates, depths, and normal renderings for the head mesh.
- The canonical coordinates xcan are used to look up spatial features in a TriPlanes structure, rigging the features onto the mesh surface. Together with the rasterizer output, these mapped features form the input for the ControlNet part of DiffusionAvatars.
- The second route for the expression code goes through a linear layer. It yields expression tokens that are subsequently used in a newly added cross-attention layer inside the pre-trained latent diffusion model. Intuitively, the rasterized inputs should encode pose, shape and rough expression while the direct expression conditioning hints at more detailed facial expressions.
- The final image is synthesized by iteratively denoising Gaussian noise.
Animate a DiffusionAvatar yourself
Here is an interactive viewer allowing for interpolations between four different expressions. Drag the blue cursor around to change zexp, which animates the avatar on the right.




(Quadrilateral linear interpolation between 4 cornering expressions.)
BibTeX
@inproceedings{kirschstein2024diffusionavatars,
title={Diffusionavatars: Deferred diffusion for high-fidelity 3d head avatars},
author={Kirschstein, Tobias and Giebenhain, Simon and Nie{\ss}ner, Matthias},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={5481--5492},
year={2024}
}