
Tobias Kirschstein
PhD Student, Technical University of MunichAbout Me
I am a PhD student in the Visual Computing & Artificial Intelligence Group at the Technical University of Munich, supervised by Prof. Matthias Nießner.During summer 2024, I completed a Research Scientist internship at Meta Reality Labs under the guidance of Shunsuke Saito and Javier Romero.
I am the creator and maintainer of the NeRSemble dataset, for which I built a custom multi-view setup with 16 video cameras and recorded facial expressions of over 420 individuals. Since its release, the dataset has enabled various research projects around 3D head avatars.1 Furthermore, we used the NeRSemble dataset to instantiate the first 3D head avatar benchmark.
Before starting my PhD, I completed a M.Sc. degree in Informatics at TU Munich with my Master’s Thesis focusing on Neural Rendering for novel-view synthesis on outdoor scenes using sparse point clouds. I obtained a B.Sc. degree in both Mathematics and Computer Science at the University of Passau, where I studied how Deep Learning can be used for emotion recognition from physiological signals under the supervision of Prof. Björn Schuller.
My current research interests lie in Neural Rendering, 3D Scene Representations, Dynamic 3D Reconstruction and Animatable 3D Head Avatars.
NeRSemble dataset
- Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
- Diffusion Avatars: Deferred Diffusion for High-fidelity 3D Head Avatars
- GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
- High-Quality Mesh Blendshape Generation from Face Videos via Neural Inverse Rendering
- DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
- FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
- GEM: Gaussian Eigen Models for Human Heads
- NPGA: Neural Parametric Gaussian Avatars
- 3D Gaussian Parametric Head Model
- Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
- HeadGAP: Few-shot 3D Head Avatar via Generalizable GAussian Priors
- SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
- VOODOO XP: Expressive One-Shot Head Reenactment for VR
- Stable Video Portraits
- GaussianSpeech: Audio-Driven Gaussian Avatars
- GASP: Gaussian Avatars with Synthetic Priors
- GaussianAvatar-Editor: Photorealistic Animatable Gaussian Head Avatar Editor
- GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
- Coherent 3D Portrait Video Reconstruction via Triplane Fusion
- SkyReels-A1: Expressive Portrait Animation in Video Diffusion Transformer
- GaussianAvatar-Editor: Photorealistic Animatable Gaussian Head Avatar Editor
- Learn2Control Controlling Avatar Diffusion with Learnable Gaussian Embedding
- Monocular and Generalizable Gaussian Talking Head Animation
Publications

FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
FlexAvatar creates high-quality and complete 3D head avatars from as few as a single input image. Creating a new avatar only takes 2 minutes and the result can be animated and viewed in real-time. To achieve effective joint training on both monocular and multi-view video datasets, we introduce bias sinks. These are learnable tokens that indicate from which dataset a training sample comes from. During inference, we always use the multi-view token. This design combines the generalizability from monocular data and the completeness of multi-view data.
Cite
@article{kirschstein2025flexavatar,
title={FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision},
author={Kirschstein, Tobias and Giebenhain, Simon and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2512.15599},
year={2025}
}
Cite
@article{oroz2025perchead,
title={PercHead: Perceptual Head Model for Single-Image 3D Head Reconstruction \& Editing},
author={Oroz, Antonio and Nie{\ss}ner, Matthias and Kirschstein, Tobias},
journal={arXiv preprint arXiv:2511.02777},
year={2025}
}
How to Build Digital Humans? From Priors to Photorealistic Avatars
A comprehensive state-of-the-art report on building digital humans, covering the full pipeline from 3D morphable models and parametric body priors to photorealistic neural avatars. We survey methods for face, head, and full-body avatar creation, including mesh-based representations, neural radiance fields, and 3D Gaussian splatting. The report provides a structured overview of capture setups, geometric priors, appearance modeling, and animation techniques, serving as a guide for researchers and practitioners working on digital human technology.
Cite
@article{zielonka2026star,
author = {Zielonka, Wojciech and Kirschstein, Tobias and Bolkart, Timo and Giebenhain, Simon and Sklyarova, Vanessa and Deng, Xiang and Xiang, Donglai and Saito, Shunsuke and Liu, Yebin and Nie{\ss}ner, Matthias and Thies, Justus},
title = {How to Build Digital Humans? From Priors to Photorealistic Avatars},
journal = {Computer Graphics Forum (Eurographics State-of-the-Art Report)},
volume = {45},
number = {2},
year = {2026},
}
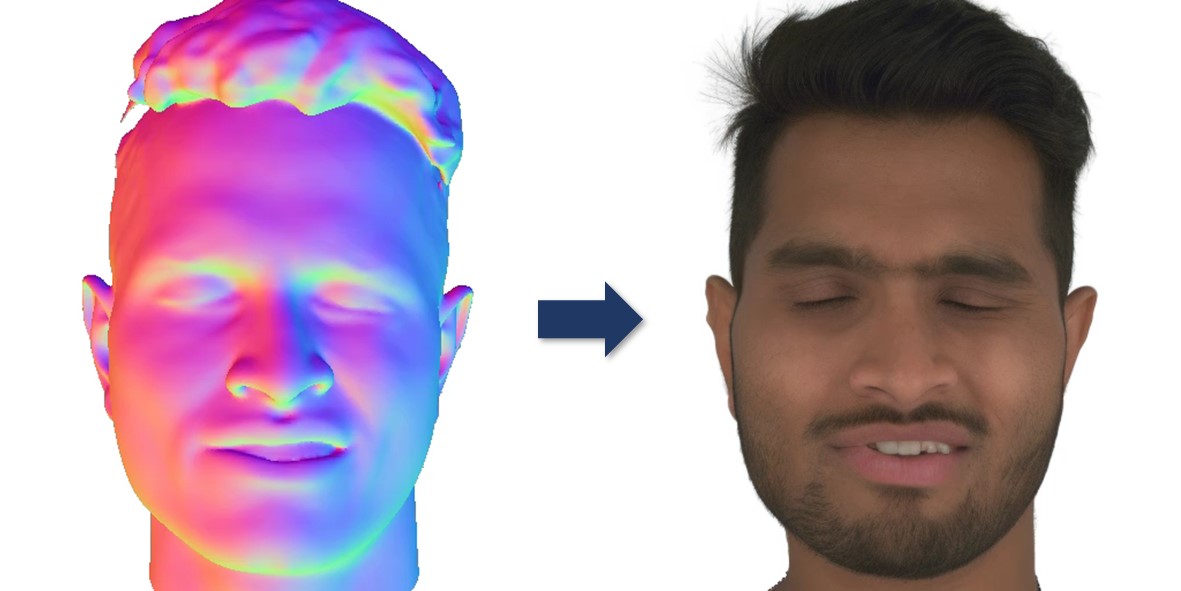
Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Given a single image, Pix2NPHM predicts high quality 3D face geometry in the form of MonoNPHM parameters by using a feed-forward transformer. For improved geometric fidelity, test-time optimization can be used to optimize against Pixel3DMM normal maps.
Cite
@article{giebenhain2025pix2nphm,
title={Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image},
author={Giebenhain, Simon and Kirschstein, Tobias and Schoneveld, Liam and Davoli, Davide and Chen, Zhe and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2512.17773},
year={2025}
}
Cite
@inproceedings{pan2025hairgs,
author = {Yimin Pan and Matthias Nießner and Tobias Kirschstein},
title = {Hair Strand Reconstruction based on 3D Gaussian Splatting},
booktitle = {36th British Machine Vision Conference 2025, {BMVC} 2025, Sheffield, UK, November 24-27, 2025},
publisher = {BMVA},
year = {2025},
url = {https://bmva-archive.org.uk/bmvc/2025/papers/Paper_1220/paper.pdf}
}
Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars
Avat3r takes 4 input images of a person’s face and generates an animatable 3D head avatar in a single forward pass. The resulting 3D head representation can be animated at interactive rates. The entire creation process of the 3D avatar, from taking 4 smartphone pictures to the final result, can be executed within minutes.
Cite
@misc{kirschstein2025avat3r,
title={Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars},
author={Tobias Kirschstein and Javier Romero and Artem Sevastopolsky and Matthias Nie\ss{}ner and Shunsuke Saito},
year={2025},
eprint={2502.20220},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.20220},
}
GaussianSpeech: Audio-Driven Gaussian Avatars
Given input speech signal, GaussianSpeech can synthesize photorealistic 3D-consistent talking human head avatars. Our method can generate realistic and high-quality animations, including mouth interiors such as teeth, wrinkles, and specularities in the eyes.
Cite
@misc{aneja2024gaussianspeech,
title={GaussianSpeech: Audio-Driven Gaussian Avatars},
author={Shivangi Aneja and Artem Sevastopolsky and Tobias Kirschstein and Justus Thies and Angela Dai and Matthias Nießner},
year={2024},
eprint={2411.18675},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.18675},
}
Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction
Pixel3DMM enables precise 3DMM tracking by predicting pixel-aligned geometric cues with a ViT, i.e. UV coordinates and surface normals. The pipeline can be initialized from a pre-trained DINOv2 backbone offering excellent generalization.
Cite
@article{giebenhain2025pixel3dmm,
title={Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction},
author={Giebenhain, Simon and Kirschstein, Tobias and R{\"{u}}nz, Rünz and Agapito,Lourdes and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2505.00615},
year={2025}
}
3DGH: 3D Head Generation with Composable Hair and Face
We present 3DGH, an unconditional generative model for 3D human heads with composable hair and face components. Unlike previous work that entangles the modeling of hair and face, we propose to separate them using a novel data representation with template-based 3D Gaussian Splatting, in which deformable hair geometry is introduced to capture the geometric variations across different hairstyles.
Cite
@article{he2025head,
title={3DGH: 3D Head Generation with Composable Hair and Face},
author={He, Chengan and Li, Junxuan and Kirschstein, Tobias and Sevastopolsky, Artem and Saito, Shunsuke and Tan, Qingyang and Romero, Javier and Cao, Chen and Rushmeier, Holly and Nam, Giljoo},
journal={ACM Transactions on Graphics},
volume={44},
number={4},
pages={1--12},
year={2025}
}
GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion
Gaussian Avatar Fusion improves 3D head avatars reconstructed from a single monocular video by employing a multi-view diffusion model to supervise novel views. The resulting 3D representation has notably higher fidelity.
Cite
@inproceedings{tang2025gaf,
title={Gaf: Gaussian avatar reconstruction from monocular videos via multi-view diffusion},
author={Tang, Jiapeng and Davoli, Davide and Kirschstein, Tobias and Schoneveld, Liam and Niessner, Matthias},
booktitle={Proceedings of the Computer Vision and Pattern Recognition Conference},
pages={5546--5558},
year={2025}
}
GGHead: Fast and Generalizable 3D Gaussian Heads
GGHead generates photo-realistic 3D heads and renders them at 1k resolution in real-time thanks to efficient 3D Gaussian Splatting. The pipeline is trained in a 3D GAN framework using only 2D images of faces.
Cite
@inproceedings{kirschstein2024gghead,
author = {Kirschstein, Tobias and Giebenhain, Simon and Tang, Jiapeng and Georgopoulos, Markos and Nie\ss{}ner, Matthias},
title = {{GGHead: Fast and Generalizable 3D Gaussian Heads}},
year = {2024},
isbn = {9798400711312},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3680528.3687686},
doi = {10.1145/3680528.3687686},
booktitle = {SIGGRAPH Asia 2024 Conference Papers},
articleno = {126},
numpages = {11},
keywords = {3D GAN, 3D head prior, 3D Gaussian Splatting},
series = {SA '24}
}
NPGA: Neural Parametric Gaussian Avatars
NPGA creates an animatable and photo-realistic 3D Gaussian representation from multi-view video recordings of a person’s head. The avatar can be animated via NPHM’s expression codes. To obtain high-quality results, NPGA models facial expressions in two ways: NPHM’s deformation field models coarse expressions while a second, learnable deformation field models the residual detailed expressions.
Cite
@inproceedings{giebenhain2024npga,
author = {Giebenhain, Simon and Kirschstein, Tobias and R\"{u}nz, Martin and Agapito, Lourdes and Nie\ss{}ner, Matthias},
title = {{NPGA: Neural Parametric Gaussian Avatars}},
year = {2024},
isbn = {9798400711312},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3680528.3687689},
doi = {10.1145/3680528.3687689},
booktitle = {SIGGRAPH Asia 2024 Conference Papers},
articleno = {127},
numpages = {11},
keywords = {Virtual avatars, 3D Gaussian splatting, Data-driven animation, 3d morphable models},
location = {
},
series = {SA '24}
}
DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars
DiffusionAvatar uses diffusion-based, deferred neural rendering to translate geometric cues from an underlying neural parametric head model (NPHM) to photo-realistic renderings. The underlying NPHM provides accurate control over facial expressions, while the deferred neural rendering leverages the 2D prior of StableDiffusion, in order to generate compelling images.
Cite
@inproceedings{kirschstein2024diffusionavatars,
title={DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars},
author={Kirschstein, Tobias and Giebenhain, Simon and Nie{\ss}ner, Matthias},
booktitle={Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
GaussianAvatars rigs 3D Gaussians to a parametric mesh model for photorealistic avatar creation and animation. During avatar reconstruction, the morphable model parameters and Gaussian splats are optimized jointly in an end-to-end fashion from video recordings. GaussianAvatars can then be animated through expression transfer from a driving sequence or by manually changing the morphable model parameters.
Cite
@article{qian2023gaussianavatars,
title={GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians},
author={Qian, Shenhan and Kirschstein, Tobias and Schoneveld, Liam and Davoli, Davide and Giebenhain, Simon and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2312.02069},
year={2023}
}
MonoNPHM: Dynamic Head Reconstruction from Monoculuar Videos
MonoNPHM is a neural parametric head model that disentangles geomery, appearance and facial expression into three separate latent spaces. Using MonoNPHM as a prior, we tackle the task of dynamic 3D head reconstruction from monocular RGB videos, using inverse, SDF-based, volumetric rendering.
Cite
@inproceedings{giebenhain2024mononphm,
author={Simon Giebenhain and Tobias Kirschstein and Markos Georgopoulos and Martin R{\"{u}}nz and Lourdes Agapito and Matthias Nie{\ss}ner},
title={MonoNPHM: Dynamic Head Reconstruction from Monocular Videos},
booktitle={Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads
NeRSemble reconstructs high-fidelity dynamic radiance fields of human heads. We combine a deformation for coarse movements with an ensemble of 3D multi-resolution hash encodings. These act as a form of expression-dependent volumetric textures that model fine-grained, expression-dependent details. Additionally, we propose a new 16 camera multi-view capture dataset (7.1 MP resolution and 73 frames per second) containing 4700 sequences of more than 220 human subjects.
Cite
@article{kirschstein2023nersemble,
author = {Kirschstein, Tobias and Qian, Shenhan and Giebenhain, Simon and Walter, Tim and Nie\ss{}ner, Matthias},
title = {NeRSemble: Multi-View Radiance Field Reconstruction of Human Heads},
year = {2023},
issue_date = {August 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {42},
number = {4},
issn = {0730-0301},
url = {https://doi.org/10.1145/3592455},
doi = {10.1145/3592455},
journal = {ACM Trans. Graph.},
month = {jul},
articleno = {161},
numpages = {14},
}
NPHM: Learning Neural Parametric Head Models
NPHM is a field-based neural parametric model for human heads, which represents identity geometry implicitly in a cononical space and models expressions as forward deformations. The SDF in canonical space is represented as an ensemble of local MLPs centered around facial anchor points. To train our model, we capture a large dataset of complete head geometry containing over 250 people in 23 expressions each, using high quality structured light scanners.
Cite
@inproceedings{giebenhain2023nphm,
author={Simon Giebenhain and Tobias Kirschstein and Markos Georgopoulos and Martin R{\"{u}}nz and Lourdes Agapito and Matthias Nie{\ss}ner},
title={Learning Neural Parametric Head Models},
booktitle = {Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}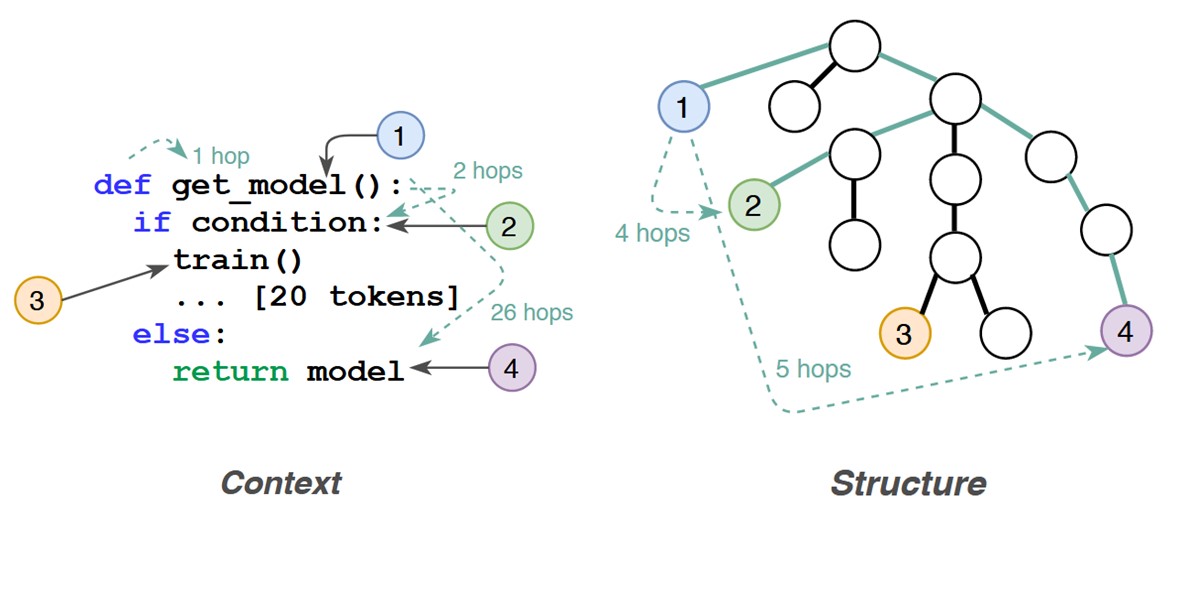
Language-agnostic representation learning of source code from structure and context
We present CodeTransformer, which combines source code (Context) and parsed abstract syntax trees (ASTs; Structure) for representation learning on code. Code and Structure are two complementary representations of the same computer program, and we show the benefit of combining both for the task of method name prediction. To achieve this, we propose an extension to transformer architectures that can handle both graph and sequential inputs.
Cite
@inproceedings{zuegner2021codetransformer,
author = {Daniel Z{\"{u}}gner and
Tobias Kirschstein and
Michele Catasta and
Jure Leskovec and
Stephan G{\"{u}}nnemann},
title = {Language-Agnostic Representation Learning of Source Code from Structure and Context},
booktitle = {9th International Conference on Learning Representations, {ICLR} 2021,
Virtual Event, Austria, May 3-7, 2021},
year = {2021},
url = {https://openreview.net/forum?id=Xh5eMZVONGF},
}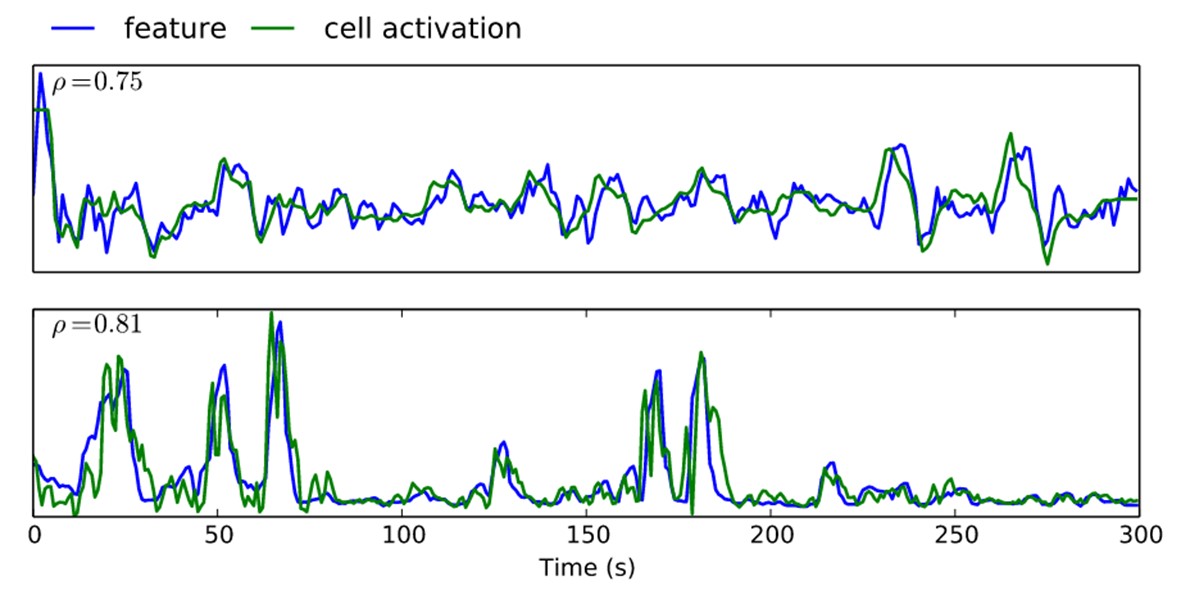
End-to-end learning for dimensional emotion recognition from physiological signals
We show that end-to-end Deep Learning can replace traditional feature engineering in the signal processing domain. Not only does a combination of convolutional layers and LSTMs perform better for the task of emotion recognition, we also demonstrate that some cells’ activations in the convolutional network are highly correlated with hand-crafted features.
Cite
@inproceedings{keren2017end,
title={End-to-end learning for dimensional emotion recognition from physiological signals},
author={Keren, Gil and Kirschstein, Tobias and Marchi, Erik and Ringeval, Fabien and Schuller, Bj{\"o}rn},
booktitle={2017 IEEE International Conference on Multimedia and Expo (ICME)},
pages={985--990},
year={2017},
organization={IEEE}
}Teaching
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-3 students on the following topics:
- Better 3D Morphable Face Model
- Relightable Avatars using Neural Relighting
- Text-Conditioned Face Motion Generation
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-3 students on the following topics:
- Relightable 3D Gaussian Splatting with Raytracing
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-3 students on the following topics:
- Generative 3D Heads
- Dynamic Geometry Reconstruction
- 3D Head Segmentation
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-3 students on the following topics:
- Generalizable 3D Head Reconstruction
- Monocular 3D Head Avatars
- 3D Scene Flow
- Text-guided 3D Head Editing
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-3 students on the following topics:
- Codec Avatars for Teleconferencing
- Intuitive Face Animation through Sparse Deformation Components
- Multi-view Stereo via Inverse Rendering
- Synthetic 3D Hair Reconstruction
3D Scanning & Spatial Learning Practical
Offered and supervised projects for teams of 2-4 students on the following topics:
- 3D Face Reconstruction and Tracking
- Intuitive Speech-driven Face Animation
- Reconstructing surfaces with NeuS and Deep Marching Tetrahedra
- Multi-view 3D Hair Reconstruction
Reviewing
BMVC
- 2025: 3 papers
CVPR
- 2024: 4 papers
- 2025: 4 papers
- 2026: 4 papers (Outstanding Reviewer)
ECCV
- 2026: 4 papers
ICCV
- 2025: 4 papers (Outstanding Reviewer)
Siggraph
- 2024: 2 papers
- 2025: 4 papers
Siggraph Asia
- 2024: 5 papers
- 2025: 2 papers
TPAMI
- 2025: 1 paper